Team article by Professor Yu Kai from Shanghai Jiaotong University
Title: acoustic word embeddings for end-to-end speech synthesis (end-to-end speech synthesis based on acoustic word embedding)
Journal: Applied Sciences
Authors: Feiyu Shen, Chenpeng Du and Kai Yu,
Publication date: 27 September 2021
DOI:10.3390/app11199010
Wechat link:
https://mp.weixin.qq.com/s? __biz=MzI1MzEzNjgxMQ==&mid=2650042375&idx=2&sn=
151c5c62ae0d5583c474b10c284d5428&chksm=f1d9cac3c6ae43d556bf64fb78ad7179
03d668684fdcafaee7dd0ffd1d686fc17a573d1c6c20&token=497878244&lang=zh_CN#rd
Journal link:
https://www.mdpi.com/journal/applsci
Introduction of communication author

Professor Yu Kai
Shanghai Jiao Tong University
The main research direction is the research and industrialization of interactive artificial intelligence, speech and natural language processing and machine learning.
Speech synthesis is one of the key issues to realize human-computer interaction. Yu Kai’s team from the Cross-media Speech Intelligence Laboratory of Shanghai Jiaotong University recentlyApplied SciencesIn this paper, an end-to-end speech synthesis method based on acoustic word embedding is studied.
introduction
In recent years, the end-to-end text-to-speech synthesis (TTS) model based on sequence-to-sequence generation architecture has achieved great success in generating natural speech. In order to avoid frame-by-frame decreasing, unnatural TTS models, such as FastSpeech and FastSpeech2, are proposed to improve the speed of speech generation. However, vocabulary recognition is very important for TTS systems to generate highly natural speech, but most end-to-end TTS systems only use phonemes as input markers, ignoring the information of which vocabulary phonemes come from.
Previous studies used preset language words to embed phoneme sequences as the input of TTS system. However, because language information is not directly related to how words are pronounced, the embedding of these words hardly affects the improvement of TTS quality. In this paper, a word acoustic embedding method combined with TTS system is proposed. Experiments on LJSpeech data set show that the acoustic embedding of words significantly improves the likelihood of prosodic prediction of sonic level on training set and verification set. The subjective evaluation of the naturalness of synthesized audio shows that the system with acoustic word embedding is obviously superior to the pure TTS system and other TTS systems with preset word embedding.
design highlights
1. Propose an end-to-end TTS system based on Acoustic Word Embedding (AWE) joint training to help improve rhythm and naturalness;
2. Using the prosody modeling method based on GMM to objectively measure the prosody of synthesized audio;
3. Explore the best structure of word encoder and the best threshold of word frequency screening;
4. Subjective evaluation after the test shows that AWE is more natural than pre-trained word embedding.
End-to-end speech synthesis method based on acoustic word embedding
Part1: end-to-end speech synthesis
In this paper, FastSpeech2 is selected as the acoustic model, but prosody modeling is not explicitly considered, which makes it difficult to objectively evaluate the prosody prediction performance of TTS system without subjective listening test. Based on this, a phoneme-level prosodic prediction module is introduced into the model, which can predict the prosodic embedding distribution of each phoneme autoregressively. Compared with the standard Fastspeech2 system, it can not only improve naturalness, but also allow the logarithmic likelihood of prosodic embedding to easily and objectively evaluate the prosodic prediction performance at phoneme level, as shown in Figure 1.
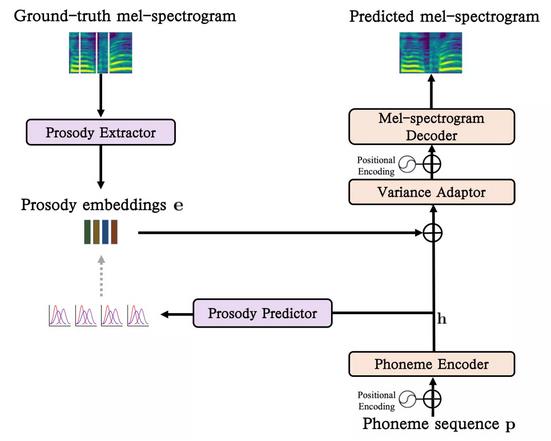
Figure 1. End-to-end speech synthesis based on GMM prosody modeling.
Part2: Acoustic Word Embedding
Nowadays, most popular TTS systems use phonemes as sound input markers, ignoring the information of which vocabulary phonemes come from. However, vocabulary recognition is very important for TTS system to generate highly natural speech. In this paper, acoustic word embedding is proposed to synthesize natural speech, and a word encoder and a word phoneme aligner are introduced into the traditional TTS system. The architecture is shown in Figure 2.
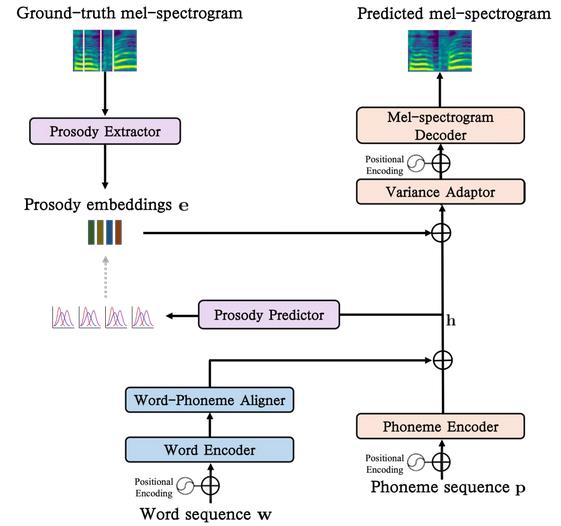
Figure 2. Model architecture with acoustic word embedding.
Experimental setup and results
1. Experimental setup
The TTS model in this paper is based on Fastspeech2 (GMM prosodic modeling). The number of Gaussian components in GMM is set to 20, and Adam optimizer and Noam learning rate scheduling strategy are used for TTS training. The researchers used 320mel-spectrogram as acoustic features, with a frame shift of 12.5ms and a frame length of 50 ms.. MelGAN is used as vocoder to reconstruct waveform.
2. Word encoder architecture
The performance of three common word encoder structures is compared.
(1) None: the baseline of the word encoder is not used;
(2) BLSTM;: a layer of 512-dimensional bidirectional LSTM;
(3) Transformer: 6-layer 512-dimensional transformer module;
(4) Conv+Transformer: one layer of 1D-CNN with a core size of 3, followed by six layers of 512-dimensional Transformer module.
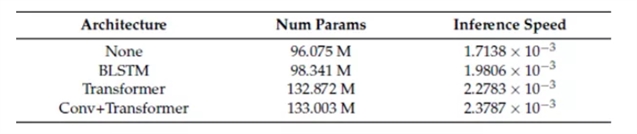
Table 1. Parameter number and reasoning speed of various encoder architectures (sec/frame).
3. Word frequency threshold

Table 2. Vocabulary and OOV under different word frequency thresholds.
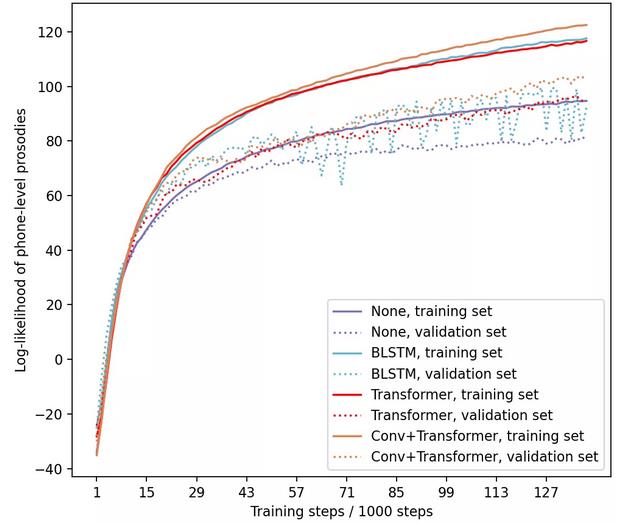
Fig. 3. Loglikelihood curve of phoneme prosody with different word frequency thresholds.
conclusion
In this paper, an innovative method of directly training acoustic embedding of words in TTS system is proposed. The phoneme sequence and the word sequence pass through two encoders respectively, which are used as the input of TTS system together, and then the two output hidden states are spliced together for phoneme-level prosodic prediction. Experiments on LJSpeech data set show that the superposition structure of convolution and Transformer is the best for word encoder. In addition, the selection of word frequency threshold should be cautious, too large or too small threshold will lead to performance degradation. Finally, this paper compares the proposed system with several works that do not use the baseline of lexical information and use pre-trained words to embed. The subjective listening test shows that the system proposed in this paper is superior to all other systems in naturalness.
Applied SciencesPeriodical introduction
Editor-in-Chief: Takayoshi Kobayashi, The University of Electro-Communications, Japan.
The subject of the journal covers all aspects of applied physics, applied chemistry, engineering, environmental and earth sciences and applied biology.

